Halo, gengs! Jadi gini nih, pernah nggak sih kalian pikirin gimana caranya menangani masalah data duplikat yang bikin ribet? Nah, ada satu metode yang bisa kita pakai untuk ngatasin itu semua, namanya adalah implementasi hashing duplikat minim. Yuk, kita simak penjelasannya lebih lanjut!
Apa Itu Implementasi Hashing Duplikat Minim?
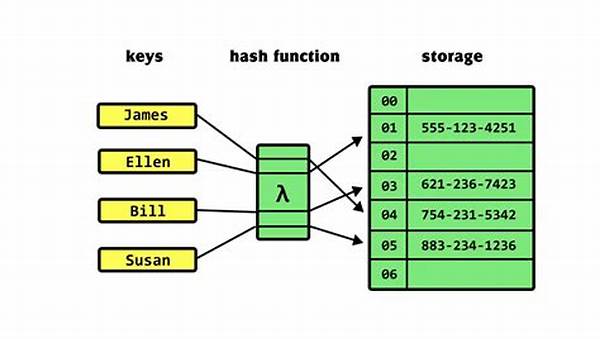
Jadi, implementasi hashing duplikat minim ini adalah teknik buat ngatur data supaya nggak banyak yang dobel atau kembar-kembar. Kebayang nggak sih kalau data kita tumpang tindih terus? Pasti ribet banget kan buat ngolahnya? Nah, makanya, hashing ini bisa bantu banget buat nyelesain masalah itu. Hashing bekerja dengan cara ngubah data menjadi kode unik yang gampang diidentifikasi, sehingga kalau ada data yang sama masuk lagi, langsung bisa ke-detect deh. Asli, ini tools yang keren banget buat menjaga data tetap efisien dan nggak makan tempat. Dengan adanya implementasi hashing duplikat minim, hidup jadi lebih asyik dan bebas drama data duplikat!
Kenapa Perlu Implementasi Hashing Duplikat Minim?
1. Efisiensi Menawan: Bayangin deh kalau tiap data tersimpan rapi, jadi kerjaan juga lebih cepat selesai.
2. Hemat Ruang: Data yang rapi kan nggak makan space banyak, otomatis storage bisa lebih awet.
3. Pencarian Gampang: Kalau data terletak rapi, nyarinya juga lebih gyap gitu gengs, nggak buang waktu.
4. Akurat dan Terpercaya: Data jadi konsisten, jadi asal-asalan pas nerima laporan cepat kebaca.
5. Sistem Lebih Agresif: Dengan implementasi hashing duplikat minim, sistem bisa responsif dan nggak lemot.
Manfaat Implementasi Hashing Duplikat Minim di Kehidupan Nyata
Kalau kita ngomongin dunia nyata, implementasi hashing duplikat minim ini penting banget diserap sama perusahaan-perusahaan yang mewadahi data customer. Terutama di dunia e-commerce sama perbankan, hashing ini semacam security yang menjaga data customer tetap valid dan jauh dari kata error. Bayangin kalau sistem langsung ke-hang gara-gara data duplikat. Kan sebel ya? Model bisnis jadi berantakan. Dengan adanya solusi hashing ini, performa sistem bisa terus terjaga. Nah, buat kalian yang bergerak di bidang data dan IT, wajib banget nih mendalami lebih jauh tentang teknik ini. Dijamin, nggak bakal nyesel deh!
Cara Kerja Implementasi Hashing Duplikat Minim
1. Data Input: Pertama, data yang masuk kudu diolah jadi kode unik.
2. Proses Unik: Semua data diolah supaya nggak ada yang dobel dan tumpang tindih.
3. Identifikasi Cepat: Ketika data yang sama ketemu, sistem langsung deteksi.
4. Integrasi Langsung: Gampang integrasi ke sistem apa aja, termasuk aplikasi bisnis.
5. Aplikasi Luas: Diterapkan ke semua platform, dari storage lokal sampai cloud computing.
Mengapa Implementasi Hashing Duplikat Minim Dibutuhin?
Dalam era digital kaya gini, serbuan data bukan cuma datang dari satu arah. Diperlukan metode mengatasi hal itu kayak implementasi hashing duplikat minim. Kita bisa sableng dalam menangani data, tapi pada masanya, semua tetap butuh sistem yang solutif. Sistem yang anti duplikat bikin semua tetap jalan dengan baik dan nggak ada kesalahan krusial. Ini solusi modern yang kudu dilirik buat proses pengolahan data yang lebih canggih dan aman. Gimana nggak keren coba, kita kerja lebih efisien tanpa perlu takut data rusak?
Kesimpulan Implementasi Hashing Duplikat Minim
Nah, gengs, ternyata implementasi hashing duplikat minim nggak cuma sekedar teknik IT biasa. Teknik ini menjadi pahlawan di balik layar yang menjaga data kita tetap rapi dan bebas dari duplikasi yang ngeribetin. Kita bisa ngandelin sistem ini terutama di sektor-sektor krusial kayak perbankan, e-commerce, dan berbagai industri lainnya. Jadi, nggak ada lagi deh cerita file yang berantakan atau pengolahan data yang tersendat. Intinya, hashing ini menolong banget siapapun yang butuh kecepatan dan akurasi data di setiap langkah operasional mereka. So, buruan deh kepoin lebih dalam tentang teknik ini ya!